Building an App Review Classifier and Visualization

At Cambridge Mobile Telematics, we’re always improving our services and products, with the goal of keeping roads and drivers safe. Understanding our consumers’ feedback and translating it into actionable insights is a powerful way to achieve this goal. At CMT, we have a rich source of feedback in the form of app reviews that consumers provide on the Google Play & App Store. To leverage this data, we’ve developed an automated pipeline to transform this data into a dashboard that displays a clear, detailed distribution of the issues our end users face.
Our Goals
We had two goals for this app review dashboard.
1. Simplicity. Unstructured reviews are hard and time-consuming to digest. It is important for anyone viewing this dashboard to get a quick, but clear idea of what our customers face without wading through thousands of reviews.
2. Accuracy and Timeliness. Anyone who looks at the dashboard should trust that it displays the most recent and relevant information.
Overview
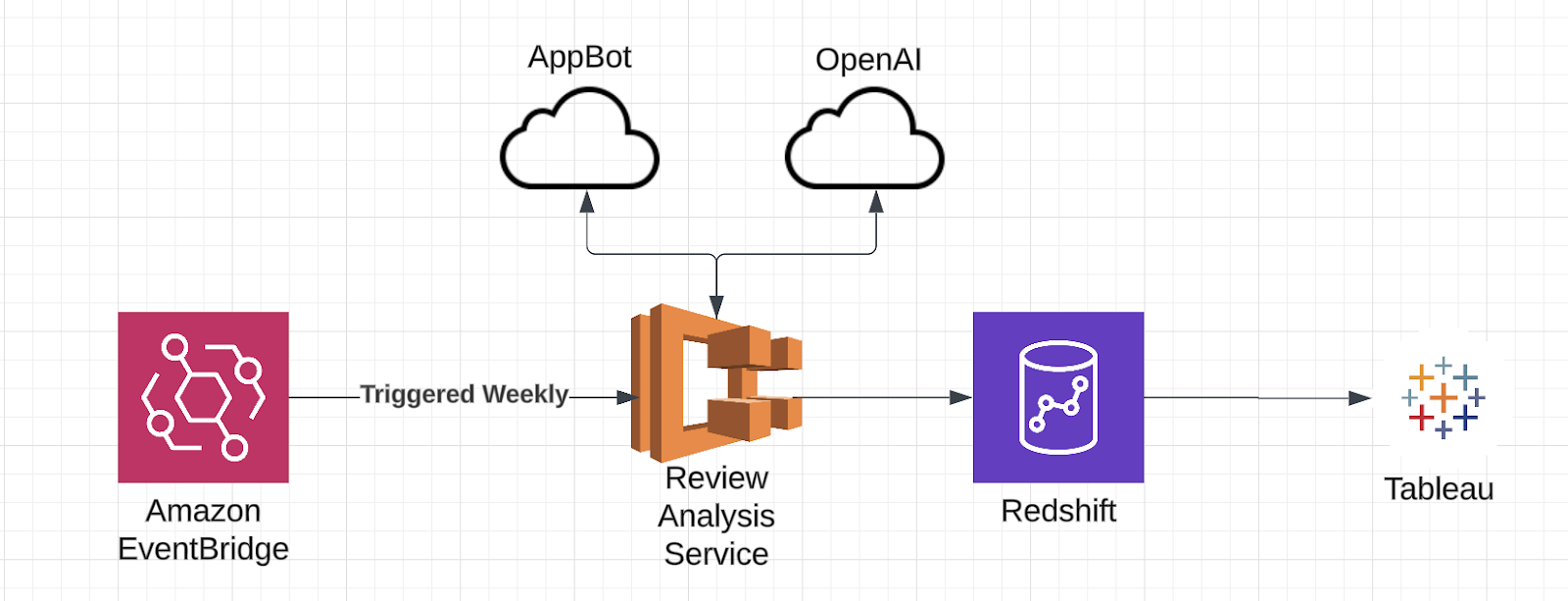
We used Tableau to create data visualizations – it is a simple solution that allows us to connect to a live relational database. To populate this database and keep it up-to-date, we developed an automated pipeline that regularly pulls and classifies app reviews into simple, but informative topics using AWS Services.
Specifically, we used an AWS EventBridge Scheduler, which can launch other AWS Services on a schedule. We targeted AWS’s Elastic Container Service (ECS), which enabled us to run a containerized application that contains the logic for pulling and classifying reviews. The combination of these two services ensures that our tables always reflect the newest feedback from our customers.
Getting the Reviews
The first task for our application was to obtain all the reviews for our apps. We used a tool called AppBot that tracks the reviews and ratings for our apps on the Apple and Google Play Store. AppBot enables us to write a software service to get all the reviews for a particular app. We ran this software for all of our apps and then processed the responses to create a list of dictionaries that contains the review information, i.e. app ratings, dates, and app versions for downstream analysis. For accuracy and to avoid redundancy, the service pulls new reviews on a daily basis – ensuring to filter out any duplicates.
Classifying the Reviews
The raw reviews alone lack sufficient structure – without a consistent format, they take time to sift through. We wanted to categorize the reviews to succinctly get an idea of the reviewer’s concerns. Additionally, these categories needed to enable actionable insights. They needed to be specific enough to help our product teams identify potential product improvements.
To create these actionable insights, our first approach was to plug a few thousand reviews into ChatGPT and ask it to produce its own categories. Despite our best prompt engineering, ChatGPT returned vague, generic categorizations that wouldn’t aid downstream decision-making. As a result, we decided to use our team’s own domain knowledge to create categories that map to our specific product and technology.
To automate review categorization, we first tried to leverage OpenAI’s models by feeding a giant prompt into GPT including all of our categories and incoming reviews. However, GPT models did a poor job with the large prompts and multi-step tasks. Thus, we decided to categorize each review individually. We then had two options:
1. Given a review, input all categories and ask the model to select the relevant categories. This was still a large multi-step task, making the results complex and inaccurate.
2. Given a review, iterate through all categories and give the model a binary yes / no task for whether each category makes sense. This option was far too slow and costly.
To address these challenges, we opted for a hybrid approach that combined the cost-effectiveness of classifying multiple categories at once (Option 1) with the accuracy of individual category assessments (Option 2). Given a review, the software iterated through a subset of categories using a GPT model one category at a time, and returned yes/no answers for whether each category was reasonable for the review. Here is some high-level pseudocode that describes the process:
FUNCTION classify_review (review text, potential categories)
SET review_categories to empty list
FOR EACH category in potential categories:
IF GPT predicts category is accurate:
ADD category to review_categories
RETURN review_categories
To cut the categories to only the most likely ones, we used the Retrieval-Augmented Generation (RAG) framework. In order to do this, we first generate a set of synthetic reviews. For example, for the “Missing Trips” category, we would produce an artificial set of reviews that discuss the app not recording a user’s drives. Using these synthetic reviews, we created a review database (vector store). For each review we received, we first query the database for the ‘closest’ synthetic reviews using embeddings that encode the contextual meaning of words, or tokens. In this case, when we talk about two reviews being ‘close’, we mean that the vectors that encode both of them are mathematically similar. Taking the n most similar reviews, we can look at their categories to produce a set of selected categories to prompt the GPT model with the yes/no classification task. Here is an overview of this process:
FUNCTION get_relevant_categories_rag (review_text, review_database):
GET review_embedding of review_text
QUERY n similar_reviews from review_database using review_embedding
SET relevant_categories to categories of similar_reviews
RETURN unique relevant_categories
Storing the Reviews
We needed to efficiently store these categorized reviews. Given that we had a fixed structure of reviews and their corresponding metadata, we wanted to use a relational table to allow us to query relevant information using SQL. While it seemed like the simplest solution to use one table, it undermined some of the inherent advantages of a relational database. It would have compromised data integrity by allowing invalid entries, and complicated queries by forcing us to parse unstructured data within a single cell. This parsing is particularly an issue for reviews that span many categories. As a result, we used a two table solution. This structure enforces data validation at the database level, and optimizes query performance, ensuring Tableau seamlessly connects and analyzes the data with a simple JOIN operation. This eliminates the need for complex data processing and enables efficient exploration of the data. In addition to the categorized information, we also store the raw reviews. This enables us to perform further analysis, dive deeper into specific categories, or apply new classification techniques in the future as needed.
Conclusion
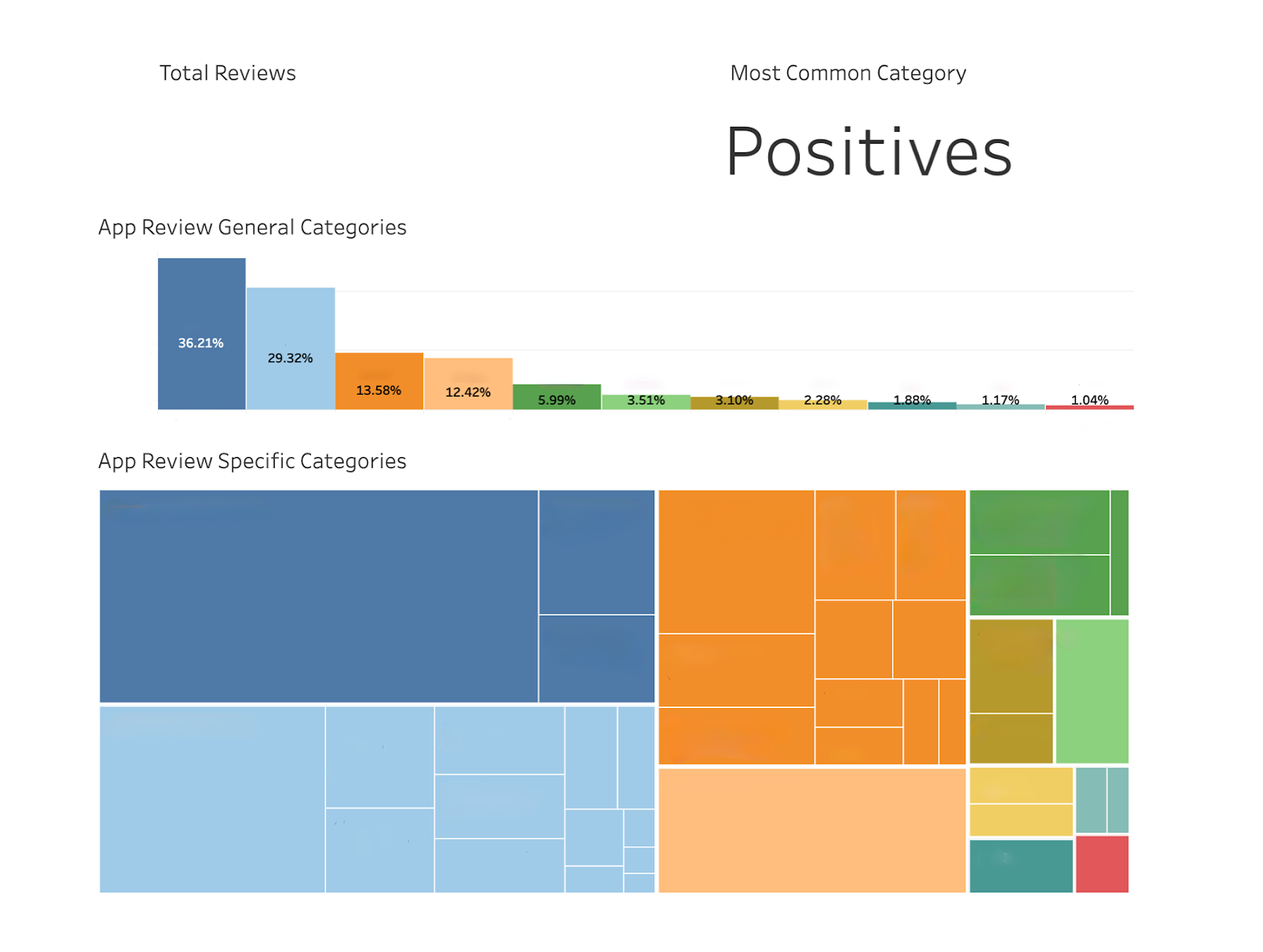
The resulting interactive dashboard, as shown above*, enables our product teams to efficiently look at app health across all customers, apps, devices, etc. This dashboard has become an invaluable tool for our product development and customer success teams. By providing a clear, real-time understanding of user feedback, we are able to prioritize improvements and create strong team objectives. We’re excited to continue refining this system and explore new ways to produce actionable insights from our customers’ needs.
*Categories have been intentionally hidden
About The Contributors Dhruv Chittamuri, Julian Sun, Bradley Werntz