Scaling Deep Learning Workflows with EKSRay: Leveraging DDP and FSDP on Ray and Kubernetes
Deep Learning has evolved to handle more complex models and larger datasets than ever before. At CMT, we leverage this technology to power telematics solutions that enhance road safety and driver behavior. Our AI-driven platform, DriveWell Fusion®, gathers sensor data from millions of IoT devices and applies advanced deep learning techniques to generate comprehensive insights into vehicle and driver behavior. This data-driven approach introduces unique challenges when it comes to scaling our systems effectively.
One of the most effective ways we scale neural network training on massive datasets is by using Distributed Data Parallelism (DDP). DDP lets us split the training of large neural networks across multiple GPUs, drastically speeding up the process and enabling us to train models that would otherwise be too large for a single machine.
While DDP offers powerful scaling capabilities, it can become complex to manage these large-scale training jobs across a GPU cluster. You quickly encounter challenges including resource allocation, job synchronization, and scaling that create operational headaches and hinder productivity.
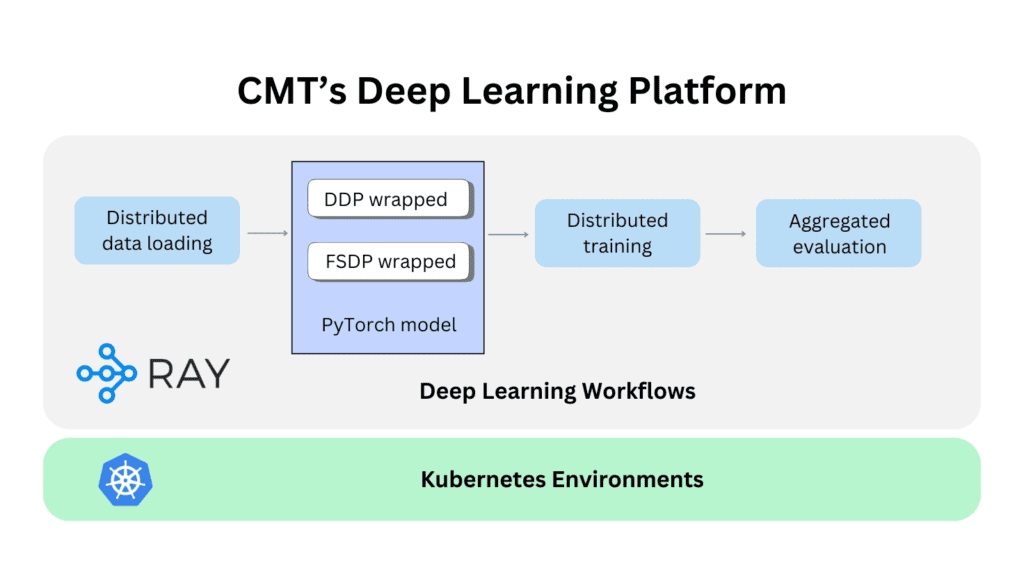
To address these challenges, CMT’s data science team developed EKSRay. It’s a powerful platform built on the Ray framework and deployed on Kubernetes environments such as Amazon EKS (Elastic Kubernetes Service). EKSRay combines the power of distributed computing with the flexibility and scalability of cloud resources, all within a streamlined Kubernetes architecture. It simplifies GPU resource management, job orchestration, and synchronization, making it the perfect solution for our team to scale DDP training jobs.
In this blog post, we’ll explore how we use EKSRay to transform CMT’s deep learning workflows. We’ll highlight its benefits for running large-scale training jobs on GPU clusters, reducing overhead, and streamlining the entire machine learning pipeline.
Why we chose Ray
After evaluating our options, we chose Ray because it is an open-source distributed computing framework that enables scalable machine learning workflows from training large models to hyperparameter tuning and distributed evaluation. It abstracts away the complexities of distributed programming, offering an intuitive interface to manage parallel and distributed tasks.
Moreover, Ray supports out-of-the-box integrations with popular deep learning libraries, offers tools for model parallelism, and automates hyperparameter optimization.
We knew that training deep learning models at scale would require a robust and efficient infrastructure, and that using Ray on an EKSRay cluster would allow us to seamlessly distribute training across multiple GPUs.
How we used Ray to train neural networks on an EKSRay cluster
Setting Up the EKS-Ray Cluster
Before training begins, we first set up an EKS cluster with GPU worker nodes and integrated Ray for distributed execution.
Deploying a Kubernetes cluster on AWS was straightforward, and once deployed, we integrated Ray into the Kubernetes environment to enable easy workload management. Ray’s Kubernetes Operator simplified the deployment process, and its Autoscaler dynamically adjusted resource allocation based on workload demand, ensuring optimal compute efficiency.
Define a DataLoader in Ray
We needed to ensure efficient data loading for handling CMT’s large-scale datasets, as it directly influences the performance of data processing pipelines and machine learning workflows. To do this, we used Ray’s ray.data module to load and transform data across a cluster. By parallelizing data ingestion, it enhanced our throughput while minimizing memory overhead. It also supported real-time preprocessing and ensured each batch is processed on-the-fly before entering the training pipeline. This lets us eliminate bottlenecks and optimize resource utilization for smoother and more efficient data workflows.
Train and Evaluate a Neural Network with Distributed Data Parallelism
After we prepared the dataset, our next step was to distribute training and evaluation across multiple GPUs using Ray’s TorchTrainer. This framework automatically partitioned our workloads across nodes, optimizing computation and memory usage. We also leveraged PyTorch’s powerful DDP module for efficient gradient synchronization across GPUs that reduced training time and maintained accuracy.
While PyTorch’s DDP gives us a robust, low-level mechanism for multi-GPU synchronization, we quickly saw that Ray’s TorchTrainer lifts much of that complexity off our shoulders. It handles the nitty-gritty of workload partitioning and meshes perfectly with our cluster resource management, making scaling distributed training across diverse environments a breeze.
During training, we actively aggregated evaluation metrics across batches and GPU nodes. Using the torchmetrics library, we crafted a custom MetricsManager to track metrics for our training, validation, and test datasets. With real-time evaluation data in hand, we dynamically adjusted batch sizes and learning rates to keep our model performance on point.
We also took full advantage of Ray’s fault tolerance and checkpointing capabilities, which gave us that extra layer of reliability. If a node fails, this allows us to resume training from the last saved state without missing a beat, ensuring our process runs smoothly and continuously.
Extending EKSRay to Fully Sharded Data Parallel
To push training efficiency even further and scale up to larger models, we extended EKSRay to support Fully Sharded Data Parallel (FSDP). Unlike DDP, which replicates the entire model across multiple GPUs, FSDP shards model parameters, gradients, and optimizer states across GPUs. This approach dramatically reduces memory overhead, making it ideal for training large models with billions of parameters while keeping memory resources in check.
We found that modifying our DDP training script to use FSDP in Ray required only a few key tweaks. Both approaches leverage ray.train.torch.TorchTrainer for distributed training, but the main difference lies in how we wrap our model.
To efficiently shard the model’s parameters using FSDP, we turned to PyTorch’s fsdp.wrap.transformer_auto_wrap_policy module. This smart policy automatically wraps each custom model layer or block into a single FSDP instance, ensuring that our model’s parameters are properly distributed across the available GPUs.
Below is some sample code that shows how we modified our DDP training script to use FSDP for efficient distributed training with Ray:

Conclusion
At CMT, we’re proud of how EKSRay exemplifies a robust and scalable approach to modern deep learning workflows. We built EKSRay by seamlessly integrating Ray’s distributed computing capabilities with Kubernetes’ dynamic resource management to tackle the challenges of multi-GPU coordination and resource allocation head-on.
We initially developed EKSRay for our own needs, but by basing it on the open-source Ray framework, we ensured that its scalable architecture can be adapted by any organization. Whether you’re deploying on AWS, Google Kubernetes Engine, Azure Kubernetes Service, or an on-premises cluster, the principles of distributed training and dynamic resource allocation remain universally applicable. We’re excited that this flexibility empowers businesses of all sizes to harness the power of distributed deep learning without being locked into a proprietary solution.
As deep learning models and datasets continue to grow in complexity, we believe platforms like EKSRay are essential for pushing the boundaries of what’s possible. At CMT, we remain committed to exploring innovative solutions that drive efficiency and performance in distributed training environments.
About The Author